Overview¶
What is a “batch” anyway? That seems to be one of those terms which means something specific in various contexts, but the meanings don’t always line up. So let’s define it within the Rattail context:
A “batch” is essentially any set of “pending” data, which must be “reviewed” by an authorized user, and ultimately then “executed” - which causes the data set to go into production by way of updating the various systems involved.
This means that if you do not specifically need a review/execute workflow, then you probably do not need a batch. It also means that if you do need a batch, then you will probably also need a web app, to give the user an actual way to review/execute. (See also Web Layer.) Most of the interesting parts of a batch however do belong to the Data Layer, so are described here.
Beyond that vague conceptual definition, a “batch” in Rattail also implies the use of its “batch framework” - meaning there is a “batch handler” involved etc.
And here is something hopefully worth 1000 words:
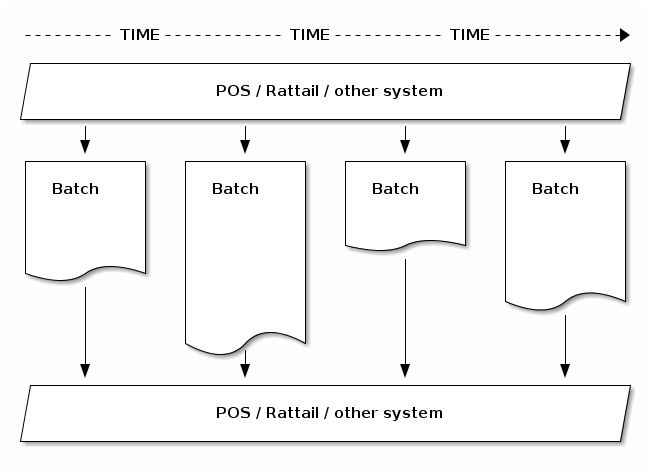
Batch Workflow¶
All batches have the following basic workflow in common:
batch is created
if applicable, batch is initially populated from some data set
batch is reviewed and if applicable, further modified
batch is executed
In nearly all cases, the execution requires user intervention, meaning a batch is rarely “created and executed” automatically.
Batch vs. Importer¶
Let’s say you have a CSV of product data and you wish to import that to the
product table of your Rattail DB. Most likely you will use an “importer”
only, in which case the data goes straight in.
But let’s say you would prefer to bring the CSV data into a “batch” within the
DB instead, and then a user must review and execute that batch in order for the
data to truly update your product table.
That is the essential difference between an importer and a batch - a batch will always require user intervention (review/execute) whereas a plain importer never does.
Now, that said, what if you have a working importer but you would rather “interrupt” its process and introduce a user review/execute step before the data was truly imported to the target system? Well that is also possible, and we refer to that as an “importer batch” (creative, I know).
Batch from Importer¶
aka. “importer batch”
This is relatively less common in practice, but it serves as a good starting point since we already mentioned it.
With an “importer batch” the data in question always comes from whatever the
“source” (host) is for the importer. The schema for the batch data table is
kept dynamic so that “any” importer can produce a batch, theoretically. Each
importer run will produce a new table in the DB, columns for which will depend
on what was provided by the importer run. Such dynamic batch data tables are
kept in a separate (batch) schema within the DB, to avoid cluttering the
default schema. (Note that the batch schema must be explicitly created
if you need to support importer batches.)
The execution step for this type of batch is also relatively well-defined. Since the batch itself is merely “pausing” the processing which the importer normally would do, when the batch is executed it merely “unpauses” and the remainder of the importer logic continues. The only other difference being, the importer will not read data from its normal “source” but instead will simply read data from the batch - but from there it will continue as normal to write data to the target/local system.
Batch from User-Provided File¶
More typically a batch will be “created” when a user uploads a data file. With this type of batch, the data obviously comes from the uploaded file, but it may be supplemented via SQL lookups etc. The goal being, take what the user gave us but then load the “full picture” into the batch data tables.
User then will review/execute as normal. What such a batch actually does when executed, can vary quite a bit.
Note that in some cases, a user-provided file can be better handled via importer only, with no batch at all unless you need the review/execute workflow.
Batch from User-Provided Query¶
In this pattern the user starts by filtering e.g. the Products table grid according to their needs. When they’re happy with results, they create a new batch using that same query. So this defines the data set for the batch - it is simply all products matching the query.
Note that Products is the only table/query supported for this method thus far. It is possible to create multiple batch types with this method.
User then will review/execute as normal. What such a batch actually does when executed, can vary quite a bit. A common example might be to create a Labels batch from product query, execution of which will print labels for all products in the batch.
Batch from Custom Data Set¶
In this pattern the logic used to obtain the data is likely hard-coded within the batch handler.
For instance let’s say you need a batch which allowed the user to generate “Please Come Back!” coupons for all active members who have not shopped in the store in the past 6 months.
You should not require the user to provide a data file etc. because the whole point of this batch is to identify relevant members and issue coupons. If the batch itself can identify the members then no need for the user to do that.
So here the batch handler logic would a) create a new empty batch, then b) identify members not seen in 6 months, adding each as a row to the batch, then c) user reviews and executes per usual, at which point d) coupons are issued.